Neptune
Summary
This document covers the information to gather from AWS to interface with its Gremlin compatible endpoints to configure a Qarbine data service. The data service will use the Qarbine Gremlin driver. You can define multiple data services that use the Gremlin driver to access different Neptune databases. Once a data service is defined, you can manage which Qarbine principals have access to it and its associated Gremlin data. A Qarbine administrator has visibility to all data services.
Note- Neptune is a VPC only service! More commentary on this consideration is below.
The example catalog components use a data service named “AWS Neptune”. To use them, create such a data service with your settings as described below. Also create a data service named “Gremlin” with the same settings.
Overview
Neptune is graph data oriented which can be queried using the Gremlin or openCypher query language. Both enable complex graph query operations to be defined for the interrelated graph data. Potential commercial implementations include enhancing data analysis capabilities in social networks, improving recommendation systems, and optimizing supply chain management through more efficient graph queries.
Note that although the Qarbine Gremlin driver is used, AWS Neptune provides an openCypher endpoint as well. Thus queries referencing a data service can use either Cypher or Gremlin query syntax. More on this is with the Data Source Designer querying section of the documentation highlighted below.


AWS Neptune Values
Your AWS Neptune endpoint is used as the Qarbine server template value.
It is recommended that read-only credentials be used for Neptune access from Qarbine. If you don't already have an IAM role or user, create one in the AWS Management Console.
If your Qarbine data service does not explicitly provide credentials, the AWS SDK will attempt to locate them in the following order.
Environment Variables: The SDK first checks for credentials in the environment variables AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and optionally AWS_SESSION_TOKEN for temporary credentials.
Shared Credentials File: If no environment variables are found, the SDK then looks in the shared credentials file (˜/.aws/credentials). This file can contain multiple profiles, and the default profile is used unless a different one is specified.
AWS Config File: The SDK also checks for credentials in the AWS config file (˜/.aws/config), which might also contain multiple profiles and regions.
Instance Metadata Service (for EC2 instances): If the application is running on an EC2 instance, the SDK checks the EC2 instance metadata service to obtain the IAM role credentials assigned to the instance.
To create a new set of credentials:
- Go to the IAM console.
- Select the role or user you created.
- Attach the NeptuneReadOnlyAccess policy. This policy grants read-only access to all Neptune resources for both administrative and data-access purposes.
- Ensure that the role or user has the necessary permissions by checking the attached policies.
Use the credentials associated with the role or user to configure Qarbine access as described below.
Qarbine Configuration
Compute Node Preparation
Determine which compute node service endpoint you want to run this data access from. That URL will go into the Data Service’s Compute URL field. Its form is “https://domain:port/dispatch”. A sample is shown below.

The port number corresponds to a named service endpoint configured on the given target host. For example, the primary compute node usually is set to have a ‘main’ service. That service’s configuration is defined in the ˜./qarbine.service/config/service.main.json file. Inside that file the following driver entry is required
"drivers" :[
. . .
"./driver/gremlinDriver.js"
]
If you end up adding that entry then restart the service via the general command line syntax
pm2 restart <service>
For example,
pm2 restart main
or simply
pm2 restart all
Data Service Definition
Open the Administration Tool.
Navigate to the Data Services tab.

A data service defines on what compute node a query will run by default along with the means to reach to target data. The latter includes which native driver to use along with settings corresponding to that driver. Multiple Data Sources can reference a single Data Service. The details of any one Data Service are thus maintained in one spot and not spread out all over the place in each Data Source. The latter is a maintenance and support nightmare.
To begin adding a data service click

Enter a name and optionally a description.
Also choose the “Gremlin” driver.
The Data Service’s server template represents the Gremlin endpoint. For AWS Neptune, see
If no port is specified in the endpoint then port 8182 is used.
A partial Data Service example is shown below.
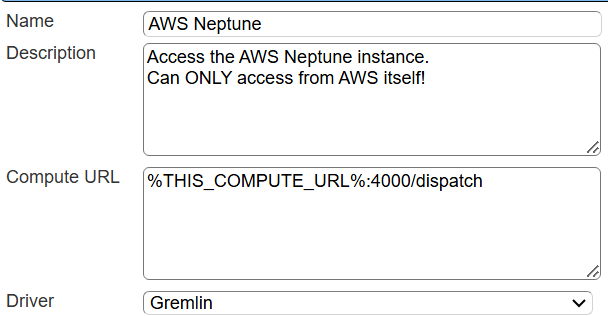

You can reference environment variables using the syntax %NAME%. Any strings should be quoted and the key\value pairs separated by commas.
You can optionally provide AWS credentials using the structure shown below.

Next, test the settings by clicking on the icon noted below.

The result should be

Save the Data Service by clicking on the image highlighted below.

The data service will be known at the next log on time. Next, see the Gremlin or AWS Neptune query interaction and any tutorial for information on interacting with graph data from Qarbine.
NOTE - The example AWS Neptune components reference the data service named “AWS Neptune”.
AWS Neptune Considerations
Accessing
A sample server template is
wss://myneptune.cluster-ro-abcdef.us-east-1.neptune.amazonaws.com:8182/gremlin
As Neptune is a VPC only service, connecting via the VPC (such as using an EC2 instance in the same VPC as the cluster) is the most common way of doing so and exposing the the cluster to the internet will not allow you to connect from a non-VPC machine via the internet. VPC only services such as Neptune are currently not exposed to the internet for such a connection.
With the above in mind, there are ways to connect to a Neptune cluster from the internet, but it involves tunneling the connection through an EC2 instance which are sometimes referred to as bastion hosts or jumpboxes, using SSH tunneling or port forwarding. This allows for the traffic to be sent through the EC2 instance (which is accessible to your local machine) and the requests are received by the Neptune cluster from the EC2 instance. Here is a 3rd party article discussing how to do this with Neptune.
https://medium.com/@ravelantunes/connecting-to-aws-neptune-from-local-environment-64c836548e89
References
https://docs.aws.amazon.com/neptune/latest/userguide/security-vpc.html